事件溯源模式
使用只可追加的存储来记录对数据所进行的所有操作,而不是存储领域数据的当前状态。该存储作为记录系统可用于实现领域对象。通过避免数据模型与业务领域之间的同步,该模式简化了复杂领域下的工作,同时改善了性能、可扩展性和响应能力。还能够提供事务数据一致性,并维护了全部的审计记录与历史,可用于修正操作。
背景与问题
大部分应用都需要和数据打交道,典型的方法是由应用维护数据的当前状态,在用户使用时对数据进行更新。例如,在传统的增删改查(CRUD)模型下,典型的数据处理过程是,从数据库中读取该数据,做一些修改后再用新值去更新数据的当前状态——通常会使用带锁的事务。
这种CRUD方法有一些局限性:
- CRUD系统在数据库上直接执行更新操作,由于需要开销,会降低系统的性能与响应能力,限制可扩展性。
- 在一个由多个用户并发操作的领域中,数据更新更有可能会起冲突,因为更新操作发生在同一条单独的数据项上。
- 除非在某个单独的日志中存在额外的审计机制来记录每个操作的细节,否则历史记录会丢失。
关于对CRUD方法局限性的更深入了解,见CRUD, Only When You Can Afford It。
解决方案
事件溯源模式对于由一系列事件驱动产生的数据定义了一套处理方法,每个事件被记录在一个只可追加的存储中。应用代码发送一系列事件,这些事件命令式地描述了数据上产生的每个操作,并持久化到事件数据库中。每个事件代表对数据的一系列变化(例如AddedItemToOrder)。
这些事件持久化在一个事件数据库中(可信的数据源),作为记录数据当前状态的系统。事件数据库通常会发布这些事件,以便通知到消费者,并由消费者进行所需的处理。例如,消费者可以在其它系统中利用这些事件来初始化一些操作任务,或者执行完成整个操作所需的其它相关动作。注意,产生事件的应用代码是与订阅事件的系统相解耦的。
事件数据库所发布事件的通常用途是在应用改变实体状态时维护实体的物化视图,以及与外部系统集成。例如,一个系统可以维护所有客户订单的物化视图,用于生成用户界面的一部分。当应用中新增订单,添加或删除订单中的商品项,以及添加配送信息时,可以对描述这些变化的事件进行处理并更新这个物化视图。
此外,任何时间点上应用都可以读取到事件历史,用来物化某个实体的当前状态,只需要重新播放与该实体相关的所有事件即可。这可以发生在需要处理某个实体对象的物化请求时,或者发生在某个计划任务中,将实体的状态以物化视图形式存储起来,以便支持展示层的需要。
下图显示了该模式的概览,包括使用事件流的一些方式,比如创建物化视图,通过事件与外部应用和系统进行集成,以及通过重新播放事件来建立特定实体的当前状态。

事件溯源模式可以提供如下这些优点:
事件是不可变的,可通过只可追加的方式进行存储。用户界面、工作流或者初始化事件的过程都可以继续进行,处理事件的任务可以在后台运行。因此,再加上由于在整个事务处理过程中不存在冲突,便可极大地改善应用的性能与可扩展性,特别是对于展示层或用户界面。
事件是描述已发生动作的一些简单对象,包含了事件在描述动作时所需的任何相关数据。事件并不直接更新数据库。它们只是被简单地记录下来以便在合适的时间进行处理。这可以简化实现和管理。
鉴于对象关系不匹配时会造成复杂数据库表的难于理解,事件对于领域专家通常是有特殊意义的。数据库表是用于表示系统当前状态的人为概念,而不是所有已发生的事件。
事件可以帮助避免引起冲突的并发更新,因为它避免了直接更新数据库中对象的需要。尽管如此,领域对象仍然要设计得能够防止造成不一致状态。
只可追加的事件存储提供了一种审计记录,可用于监控在数据库上发生的动作,以物化视图方式或者任何时刻重新播放事件的方式重新生成当前状态,有助于系统测试和调试。此外,如果需要通过修正事件来取消某些变更,可以通过对历史变更进行反向操作进行,而如果模型中只是简单存储了当前状态的话就不行了。事件列表还可用来分析应用性能和检测用户行为趋势,或者获得其他有用的业务信息。
事件存储产生事件,任务执行操作来响应这些事件。事件与任务的解耦提供了灵活性与可扩展性。任务知道事件类型与事件数据,却并不知道触发这些事件的操作。此外,每个事件可以被多任务处理。这提供了与其它服务和系统集成的方便方法,只需要监听由事件存储产生的新事件就可以了。尽管如此,事件溯源倾向于发生在非常低的层次上,有可能需要再生成一些特定的集成事件。
事件溯源经常与CQRS模式一起使用,执行数据管理任务来响应事件,以及从存储的事件中产生物化视图。
问题与注意事项
在决定如何使用该模式时需考虑以下几点:
当创建物化视图或者通过重播事件产生数据最终状态时,系统只能保证最终一致性。在应用将请求处理的结果作为事件向事件存储中添加时、事件被发布时以及事件消费者进行处理之间,是存在一定延迟的。在这期间,有可能因实体产生更多变化而产生新的事件存入事件存储中。
注:
关于最终一致性的更多信息参见Data Consistency Primer。
事件存储是信息的不变来源,所以事件数据永不应该被更新。唯一一种对实体进行撤销操作的方法是往事件存储里增添一个修正事件。如果已持久化的事件格式(而不是数据本身)需要修改,可能会难以将存储中的已有事件与新版本通过迁移进行融合。也许需要遍历所有事件进行修改才能让它们与新格式相兼容,或者对旧事件使用新格式添加生成新事件。考虑对事件结构的每个版本使用一个版本戳,用于同时维护旧事件和新事件格式。
多线程应用和多实例应用可能会同时向事件存储中存储事件。事件存储中的事件一致性极为重要,因为事件的顺序会对特定实体造成影响(实体发生变化的顺序会影响其当前状态)。为每一个事件添加时间戳有助于避免这类问题。另外一种常见的实践是为同一请求所产生的每个事件用一个自增的标识符作为标记。如果两个动作尝试为同一个实体在同一时刻添加事件,那么事件存储可以拒绝与已存在的实体标识符相同的那个事件。
对于从事件中读取信息,并不存在标准的方法或者类似SQL查询这样现成的机制。唯一能够被提取的数据就是使用事件标识符作为查询条件的一个事件流。事件ID通常与各个独立实体相对应。某个实体的当前状态只能通过重播从实体初始状态开始到现在的所有相关事件来决定。
各个事件流的长度会对系统的管理和更新带来影响。如果事件流太长,考虑在特定时间间隔为其创建快照,比如在收集到一定数量的事件之后。当前实体状态可以从快照和对快照时间点之后发生的事件进行重播而获得。关于创建数据快照的更多信息,参见Martin Fowler的企业应用架构中关于快照的文章以及Master-Subordinate Snapshot Replication。
虽然事件溯源可以将数据更新冲突的可能性减小到最低,应用仍然需要能够处理因为最终一致性和缺乏事务机制而导致的不一致性。例如,在事件存储中产生一个库存减小事件的同时下了一个要订购该商品的订单,就需要对这两个操作进行调和,通知用户或者创建一个延期发货订单。
事件的发布可能“不止一次”,所以消费者对事件的处理必须是幂等的。如果事件被多次处理,消费者不得对事件重复操作。举个例子,如果消费者有多个实例一起维护某个实体属性的聚合,比如总下单数量,那么当某个下单事件发生时,只能有其中一个实例增加下单总数。然而这并不是事件溯源的关键特性,所以通常由实现方来做决定。
何时使用该模式
在以下场景使用该模式:
- 当你想从数据中捕获“意图”、“目的”或“原因”时。例如,一个客户实体的变更,可能是由于一系列特定的事件类型所致,比如搬家、账户终止或身故等。
- 当最小化或完全避免数据更新冲突变得非常重要时。
- 当你想记录所发生的事件,并能通过重播事件来存储系统状态、回滚变更或保留历史与审计日志时。例如,当某个任务涉及多个步骤,你可能需要执行某些动作来回滚更新,并且重播某些步骤来让数据回到一致的状态。
- 当对于应用的操作来说使用事件是一种很自然的特性,而且不需要额外的开发或实现工作时。
- 当你需要将数据输入或更新过程与相应的任务相互解耦时。这会有助于增强用户界面性能,或者将事件分发给其它监听事件并需要执行动作的监听器。例如,将工资系统与报销网站集成起来,以便让事件存储中产生因站点数据更新而产生的事件,网站和工资系统都可以消费该事件。
- 当你需要在需求变化时灵活地修改物化模型和实体数据的格式时,或者(在与CQRS模式联合使用)需要采用读模型或试图来暴露数据时。
- 当与CQRS模式联合使用,并且在读模型被更新时最终一致性是可被接受的,或者从事件流中重新融合实体和数据所造成的影响是可接受的。
这种模式可能不适用于以下场景:
- 小的或简单的领域,业务逻辑很少甚至没有的系统,或者非领域系统,用传统的CRUD数据管理机制就能很好地工作。
- 需要强一致性和数据视图实时更新的系统。
- 不需要审计日志、历史和回滚、重播能力的系统。
- 极少出现底层数据更新冲突的系统。例如,系统主要用于增加数据而很少做更新。
例子
某个会议管理系统,需要跟踪记录会议的已预订数量,以便在参会者尝试预订时检查是否还有空座位。该系统可以通过至少两种方法来存储总预订数:
- 系统可以用负责维护预订信息的数据库中的一个单独实体来存储总预订数。这种方法理论上比较简单,但是如果大量参会者在短时间内涌入预订座位,会产生可扩展性问题。例如,预定期结束前最后一天或者非常临近结束时。
- 系统可以将预订和取消信息作为事件存储在事件存储中。然后通过重播这些事件来计算空余座位数。由于事件的不可变性,这种方法更容易扩展。系统只需要能从事件存储中读取数据,或者向事件存储中追加数据即可。关于预订与取消的事件信息永远不会被修改。
下图展示了如何使用事件溯源实现会议管理系统的座位预订子系统。
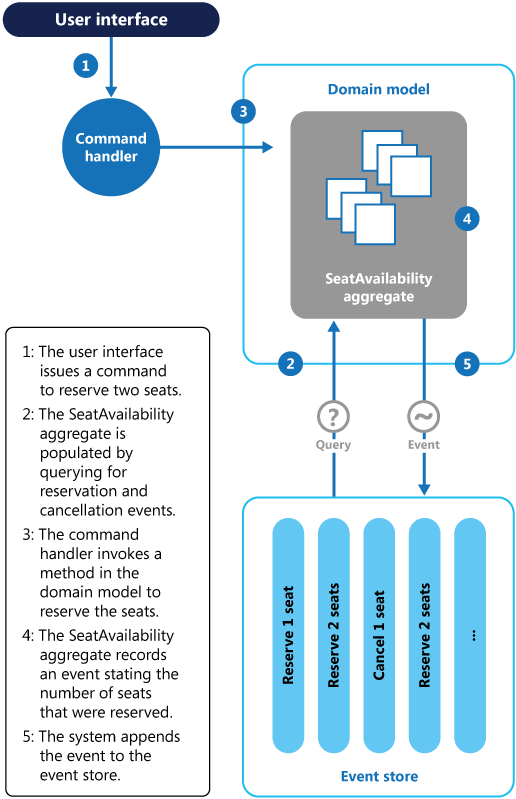
预订两个座位的动作顺序如下:
用户界面发出一个命令,要为两个参会者预订座位。一个独立的命令处理器会处理该命令。少部分逻辑会从用户界面中解耦出来,负责处理以命令形式发送的请求。
通过查询所有预订与取消事件形成包含所有会议预订信息的一个聚合。这个聚合叫作
SeatAvailability,由一个领域模型所包含,该模型对外暴露查询与修改聚合中的数据的方法。可以考虑使用快照做一些优化(这样你就不需要查询和重播所有事件来获得聚合当前状态),并在内存中维护关于该聚合的一份缓存拷贝。
命令处理器调用领域模型上暴露出的方法进行预订。
聚合
SeatAvailability记录下一个含有被预订座位数量的事件。下次这个聚合就可以通过所有预订事件来计算还剩下多少座位。系统向事件存储的事件列表中追加这个新事件。
如果用户要取消座位,系统遵循类似的过程,只是命令处理器发出的命令产生的是一个座位取消事件并追加到事件存储中。
除了能提供在扩展性方面更大的余地之外,使用事件存储还能够提供一个完整的关于会议预订与取消的历史记录或审计记录。事件存储中的事件是精确的记录。并不需要将聚合持久化到其它地方,因为系统可以轻松地重播事件并恢复任何时间点的状态。
你可以从这篇文章Introducing Event Sourcing中找到关于该例子的更多信息。
相关模式与指南
在实现该模式时,下述模式和指南可能会与之相关:
- 命令和查询责任分离(CQRS)模式。为CQRS的实现提供永久信息源的写存储通常是基于事件溯源模式而实现的。该模式描述了如何通过不同的接口将应用中读取数据与更新数据的操作互相分离。
- 物化视图模式。基于事件溯源的系统中所使用的数据存储通常不适于很好地进行高效查询。一种常见的取代方法是在固定时间间隔或者当数据变化时,预先产生一个关于该数据的视图。该模式展示了是如何做到这点的。
- 事务修正模式。事件溯源存储中已存在的数据是不会被更新的,新事件被源源不断地加入来表示实体状态的最新值。要做一个反向撤销的话,得使用事务修正,因为简单地回退到之前的状态是不可能的。该模式描述了如何撤销之前一个操作所做的工作。
- 数据一致性入门。在事件溯源中使用单独的读存储或者物化视图时,读到的数据并不是实时一致的,而仅仅是最终一致的。该入门总结了在分布式数据上维护一致性的相关问题。
- 数据分区指南。在使用事件溯源来提高可扩展性、减少冲突和优化性能时,数据通常会被分区。该指南描述了如何将数据划分为离散的分区,以及可能出现的问题。
- Greg Young的文章Why use Event Sourcing?。